
Con Artemis II/Orion la Nasa está probando un nuevo sistema de comunicaciones para misiones en el espacio. (https://www.nasa.gov/technology/space-comms/o2o/), una comunicación directa pero con algunas cuestiones técnicas interesantes para los que trabajamos en comunicaciones a diario.
Este nuevo sistema consta de un laser y unos sistemas de gimbals muy complejos para apuntar a la nave con quién van a establecer la comunicación, en este caso la cápsula Orion, ya que el punto óptico del laser es muy pequeño.
La idea es bastante sencilla,un laser apuntando a un sensor con un stack de protocolos propietarios. Esto ya existía pero con RFs, la DSN o CDSN(en el caso de china) es la Red del Espacio Profundo: Varias antenas en diferentes partes del planeta apuntando al espacio y emitiendo/escuchando mensajes hacia los dispositivos al alcance.
Pero que pasa con aquellos que están más lejos o están en lugares con conexiones intermitentes?. Para eso existen las Redes con Tolerancia al Retardo y cambia todo lo que crees que sabes en comunicaciones.
Laboratorio para poner en contexto.
Para ponernos en contexto empiezo con un laboratorio sencillo. 2 Equipos linux conectados uno contra el otro. Netem y Server. Vamos a probar que sucede con los retardos en TCP/IP
Ambos debian 13. Vamos a instalar unas herramientas que seguro ya tenés en tu equipo y probemos un poco que sucede con tcp/ip en estos escenarios.
sudo apt update && sudo apt install iperf3 iproute2
#Simular ida y vuelta
#En NETEM:
tc qdisc add dev eth0 root netem delay 300ms
#En Server:
tc qdisc add dev eth0 root netem delay 300mscon tc vamos a agregar 300ms de delay en el server y en el cliente (600ms en total) y vamos a ver que sucede.
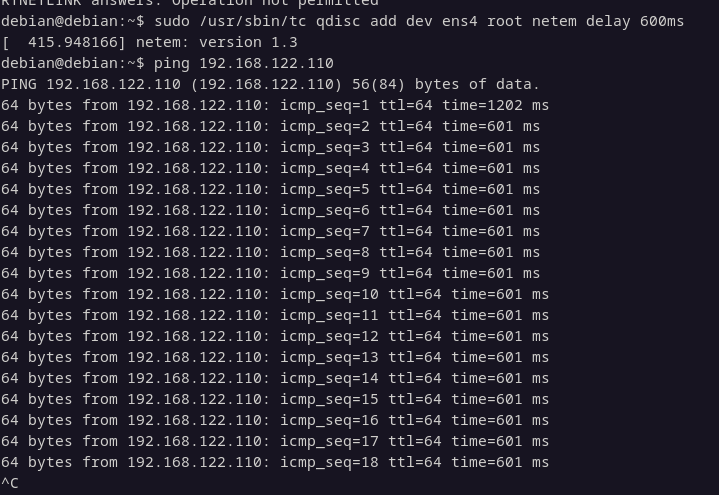
Perfecto, ya tenemos un delay bastante alto, 600ms.
Ahora agregamos a la configuración anterior 300ms más del lado del servidor y obtenemos esto:
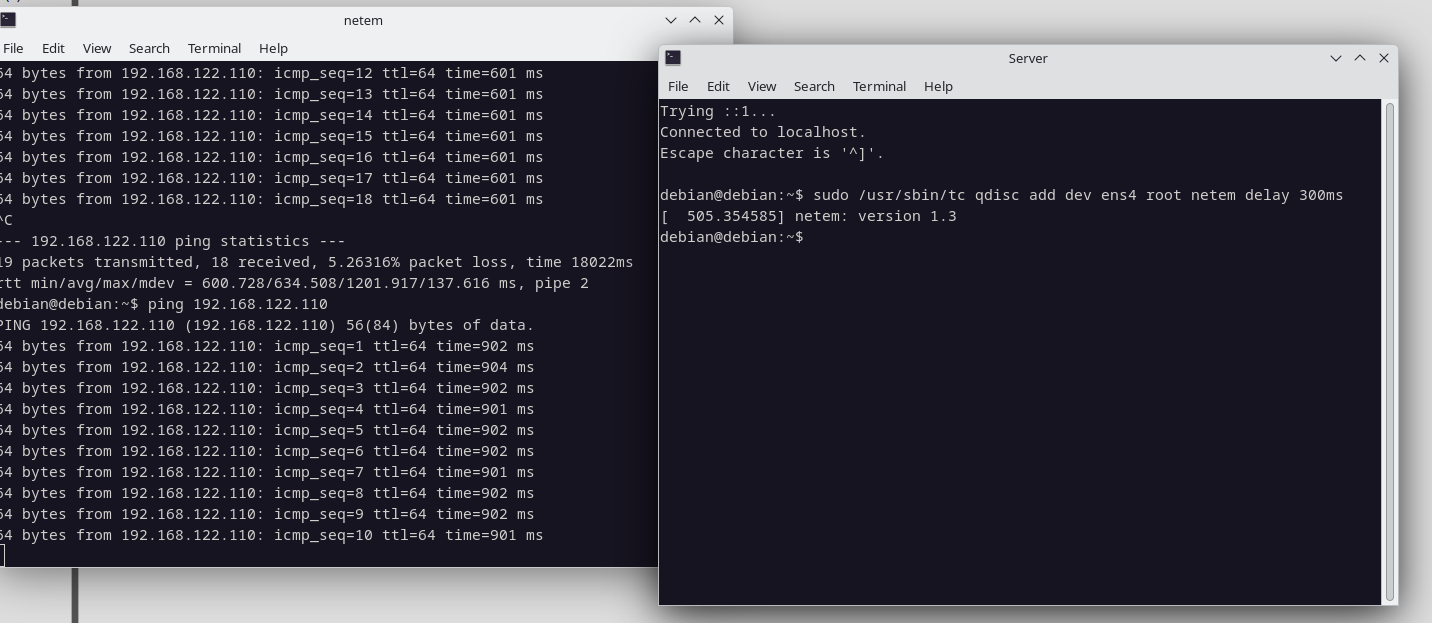
En el espacio, tenemos que incorporar un valor más que es el Jitter. Qué es el Jitter?. El jitter aparece cuando la latencia no es pareja, ejemplo:
paquete 1 → 300 ms (latencia)
paquete 2 → 350 ms
jitter = 50ms
Ese Jitter pueden ser muchas cosas, un cable dañado, una red saturada, un satelite haciendo una maniobra... ejem!.
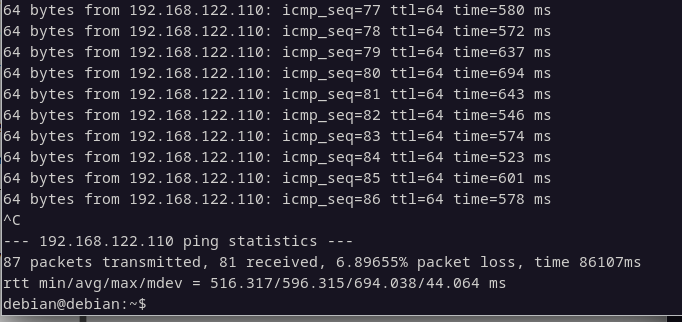
Funcionan los servicios con tanto retardo o jitter?. Bueno, la mayoría de las veces si, en una red normal en el planeta tierra. Ejemplo:
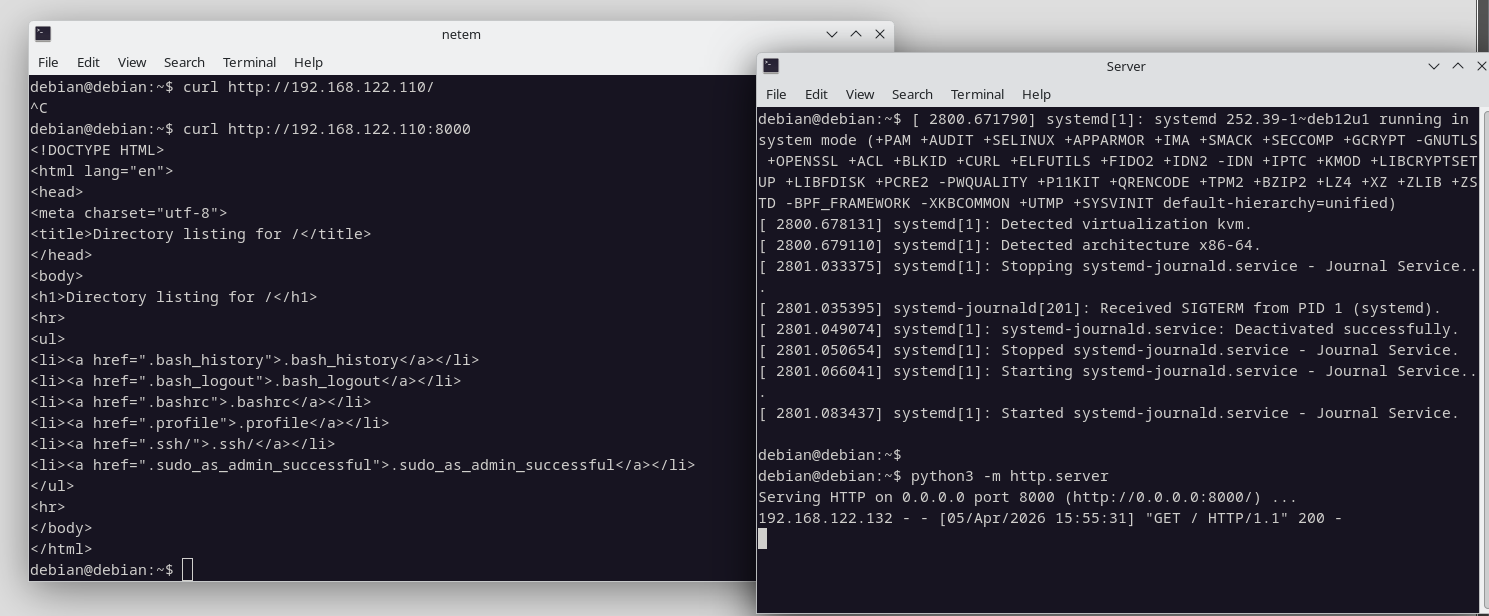
Montamos un server web con python y probamos y sip, funciona correctamente. Algo lento para ver un video de youtube pero funciona. El gran problema viene cuando el jitter y el delay se nos van de las manos.
Medimos ancho de banda:
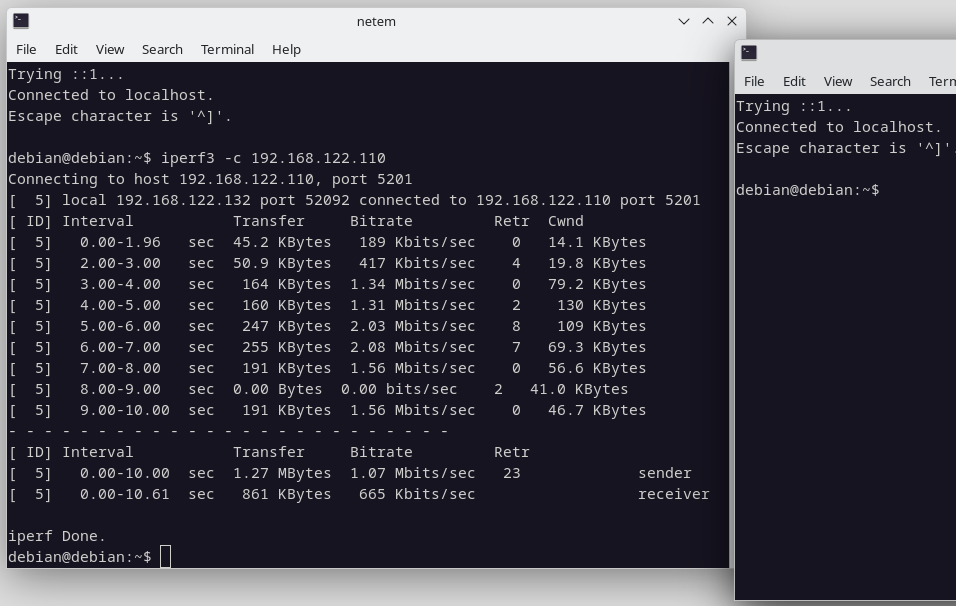
Podemos ver que con la perdida configurada hay paquetes que se reenvian, se pierden y vemos el tcp «estabilizandosé» a medida que la conexión avanza. En total 23 reenvios de paquetes.
Que pasa con UDP que no reenvia nada cuando pierde?.
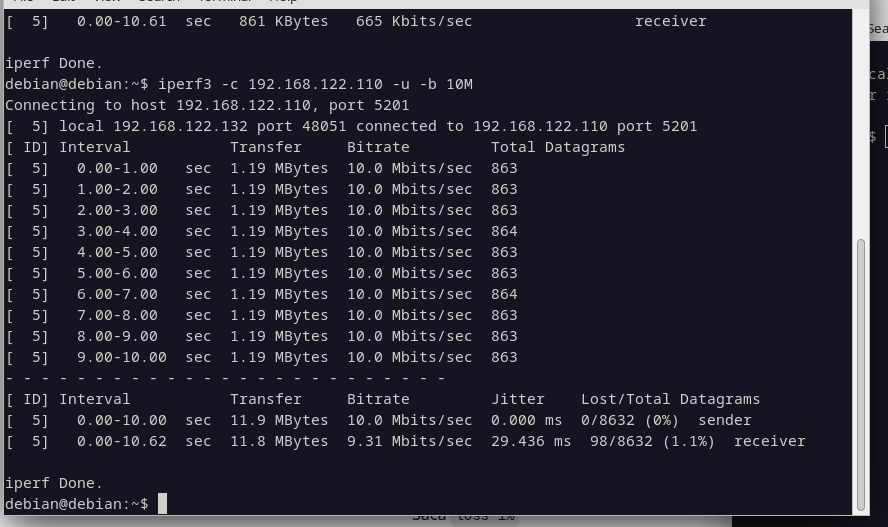
Bueno, en UDP tenemos perdida directa. En este caso la pérdida configurada 1.1%.
Qué pasa cuando el delay aumenta (O la nave se aleja?)
Para simular esto configuré tc con un delay de 10000ms en un equipo y 20000ms en el otro y vemos que sucede.
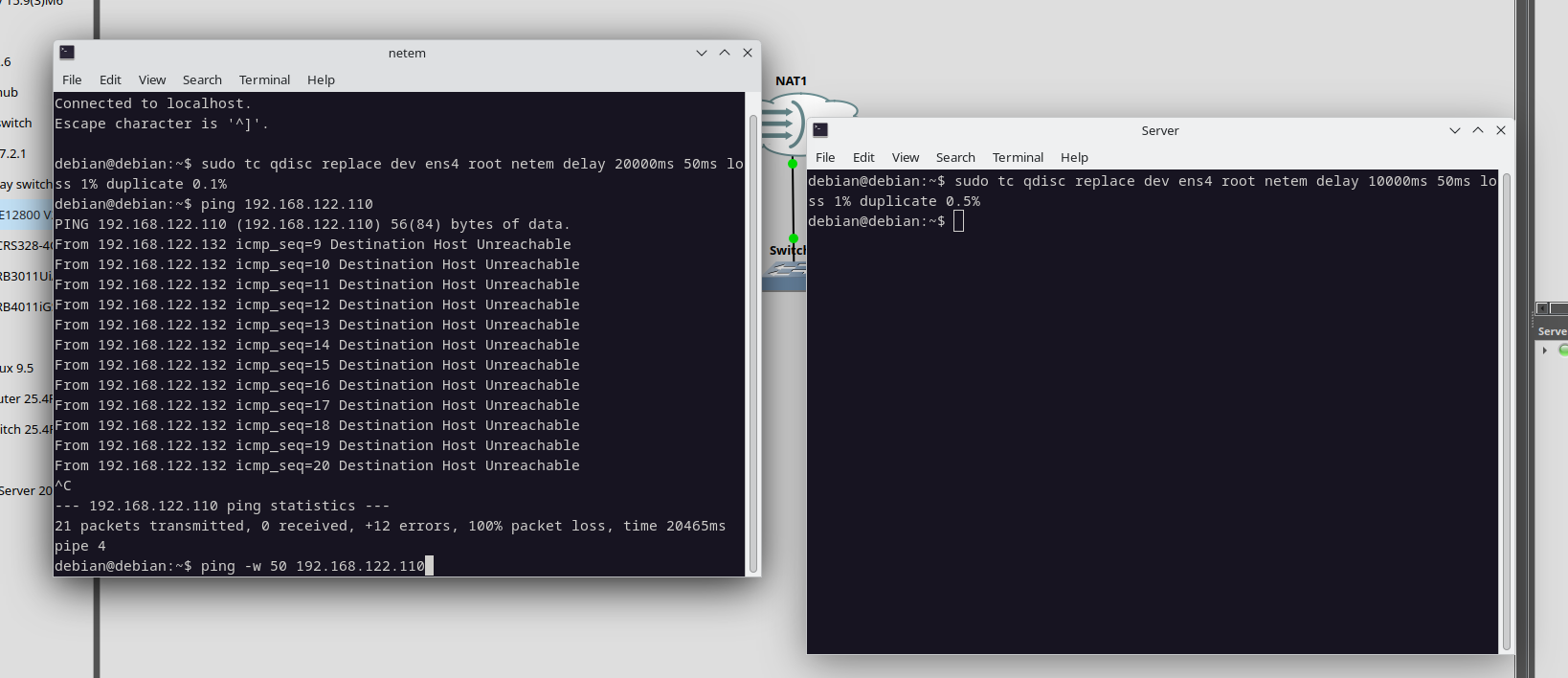
Perdimos todo, vamos a tener que cambiar el timeout y esperar que el paquete responda:
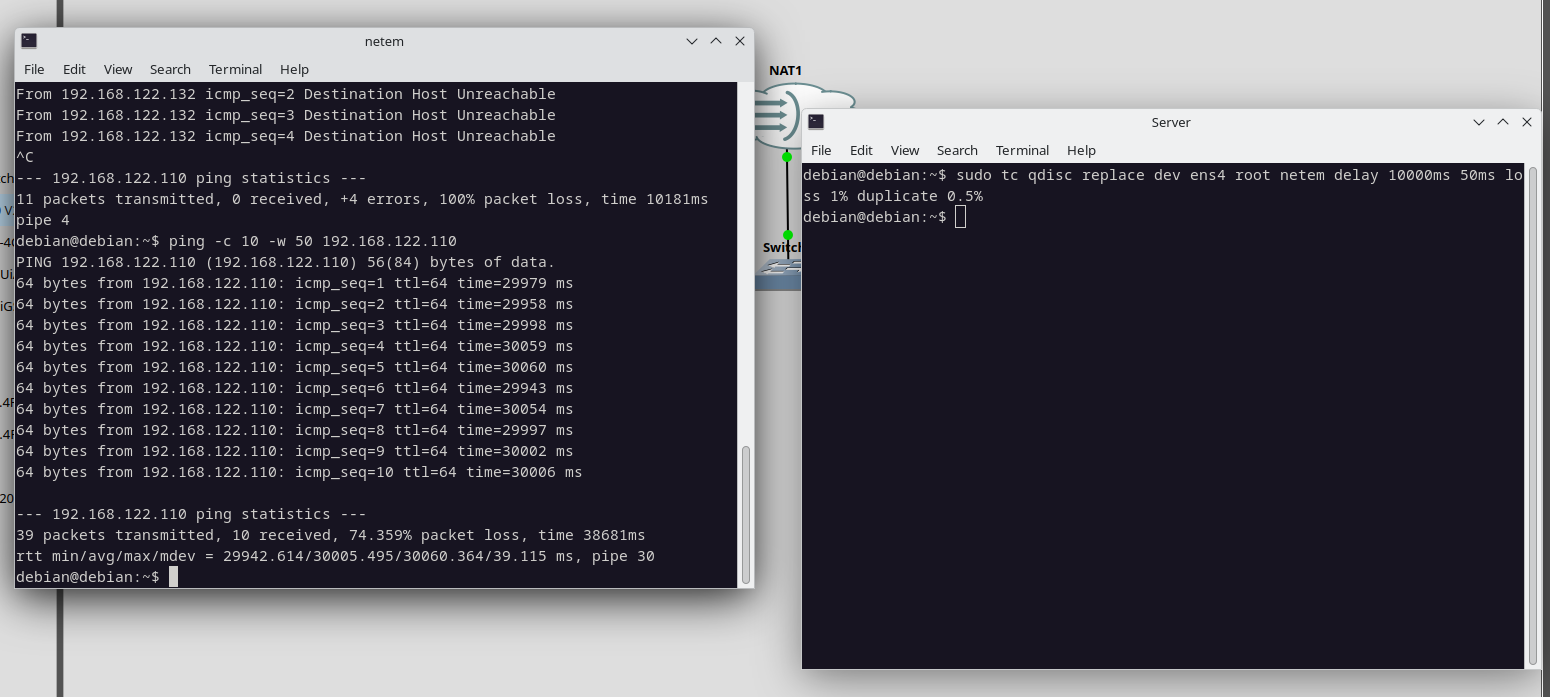
Enviamos 50 paquetes con hasta 50seg de espera y obtenemos respuesta. Con un pequeño retardo de 30 segundos entre ping… pero funciona!!!
Hasta ahora todos caso con retardos «manejables». Aumentamos el timeout, esperamos y solucionado momentamente el problema pero que pasa cuando no sabemos de cuánto será el timeout?. Ahora si estamos en contexto.
DTN – Delay/Disruption Tolerance Network
Es importante que sepas que, a partir de acá, todo lo que sabes de TCP/IP se vuelve irrelevante. Esta explicación va muy por encima pero trataré de ser «entendible».
En redes normales el flujo de datos tiene el siguiente formato: A ─── B ─── C ─── D.
Se dice que son End to End. A quiere hablar conB así que solo le habla y B escucha y responde y así secuencialmente. Sabemos con claridad cuál es el camino.
En las redes DTN: A B C y D pueden no estar disponibles cuando envio el mensaje, por lo tanto no hay camino completo al mismo tiempo. Acá es donde muere TCP/IP.
TCP/IP está orientado a la conexión y en este caso cuando se envía un mensaje probablemente no haya conexión(quizás el satelite esté cruzando Marte por detrás).
Acá entra el concepto Store – Carry – Forward. El flujo de las DTN, con este concepto, sería algo así:
[ A ] --mensaje--> (lo guarda, Store)
↓ se mueve
[ A ] ----> encuentra [B] ----> le pasa copia
↓
[B] se mueve(carry) y entra en alcance de [C]
↓
(forward)Mensaje llega a [C]Historia ejemplo
Es como llevar el mensaje «por casualidad». A conoce a B, es su vecino, le da un mensaje para D y le dice: «si encontras a alguien que lo vea daseló». B sigue su vida hasta que camino a su trabajo se encuentra con C, yendo a su trabajo también. B le entrega el mensaje de A a C y C al llegar a su trabajo, si D a ido a trabajar ese día, le entrega el mensaje, sino se lo entregará mañana, se lo guardará para que llegue el momento.
Algoritmos
En DTNs los paquetes (lo que en TCP/IP conocemos como PDU) se llaman Bundles. La estructura normal de un bundle es algo así:
+----------------------+
| Bundle |
|----------------------|
| Source |
| Destination |
| Payload |
| TTL / metadata |
+----------------------+Como te habrás dado cuenta un «nodo» dentro de esta red de comunicaciones puede en algún momento de su vida tener un montón de bundles para entregar. Cada emisión es energía que usa y cada bundle no entregado es espacio almacenado. Al hablar de sistemas de comunicación en el espacio la optimización se vuelve crítica. Es ahí donde los matemáticos se pusieron creativos y hay un montón de papers con algoritmos muy interesantes para cada caso de análisis. Acá solo voy a contarte los que encontré se usan actualmente.
Todos los algoritmos existentes caen en 4 categorías:
- Flooding (inundación)
- Replicación controlada
- Probabilísticos / históricos
- Basados en contexto
Cada uno tiene un enfoque distinto pero todos tratan de ser coherentes con el rendimiento de equipos con bajos recursos y, obviamente, la seguridad en la entrega. Todo lo que sigue es un tanto copy & paste con comentarios mios de estudio, pero muy interesante!.
* Algoritmos de inundación
Epidemic Routing
El ruteo epidémico es el enfoque más simple y sirve como base conceptual para otros algoritmos. Consiste en replicar cada mensaje en todos los nodos con los que se establece contacto.
Ventajas:
- Alta probabilidad de entrega
- Simplicidad de implementación
Desventajas:
- Consumo excesivo de ancho de banda
- Uso intensivo de almacenamiento
- Escalabilidad limitada
Variantes
Gossiping: introduce una probabilidad de reenvío para reducir la cantidad de copias.(este después evoluciona a Prophet
Anti-Entropy: optimiza el intercambio de información entre nodos para evitar duplicaciones innecesarias mediante sincronización de buffers.
* Algoritmos de replicación controlada
Estos algoritmos limitan el número de copias de cada mensaje, buscando un equilibrio entre eficiencia y probabilidad de entrega.
Spray and Wait
El algoritmo se divide en dos fases:
- Spray: el nodo fuente distribuye un número limitado de copias entre otros nodos.
- Wait: cada nodo espera encontrar directamente al destino.
Ventajas:
- Bajo consumo de recursos
- Buena eficiencia en redes móviles
Binary Spray and Wait
Optimiza la distribución de copias dividiendo progresivamente el número de copias disponibles entre nodos intermediarios.
Spray and Focus
Extiende el modelo anterior incorporando métricas inteligentes (similares a PROPHET) en la fase de reenvío.
* Algoritmos probabilísticos y basados en historial
Estos algoritmos utilizan información histórica sobre contactos entre nodos para estimar probabilidades de entrega. (los vecinos que más ves son los más probables para llevar tu mensaje)
PROPHET
Definido en RFC 6693, este algoritmo calcula una métrica denominada delivery predictability basada en:
- Frecuencia de encuentros
- Recencia de contactos
- Transitividad entre nodos
Los mensajes se transfieren hacia nodos con mayor probabilidad de alcanzar el destino.
Ventajas:
- Reducción significativa de copias
- Mayor eficiencia que Epidemic
Desventajas:
- Dependencia de patrones de movilidad relativamente estables
MaxProp
Prioriza el envío y eliminación de mensajes en función de probabilidades de entrega y congestión de la red.
RAPID
Optimiza el ruteo en función de un objetivo específico, como minimizar el retardo o maximizar la tasa de entrega.
* Algoritmos basados en contexto
Estos enfoques utilizan información adicional del entorno o del comportamiento de los nodos.
Context-Aware Routing
Incorpora variables como ubicación, velocidad y dirección de movimiento para tomar decisiones de ruteo.
Social-Based Routing
Estos algoritmos modelan la red como un grafo social.
SimBet: utiliza métricas como centralidad y betweenness para identificar nodos clave en la red.
Bubble Rap: detecta comunidades y prioriza nodos con alta centralidad dentro de ellas.
Ventajas:
- Alta eficiencia en redes humanas
- Reducción de tráfico innecesario
Desventajas:
- Complejidad computacional
- Requiere tiempo para aprender patrones
Geo-based Routing
Se basa en información geográfica (por ejemplo, GPS) para seleccionar nodos más cercanos al destino.
* Algoritmos basados en contactos programados
Contact Graph Routing (CGR)
Utilizado en entornos como comunicaciones espaciales, este algoritmo emplea un grafo de contactos predecibles para planificar rutas.
Características:
- Basado en conocimiento previo de la red
- Alta precisión en entornos controlados
* Enfoques basados en aprendizaje automático (esto ya es futuro)
Los enfoques más recientes incorporan técnicas de aprendizaje automático para predecir patrones de movilidad y optimizar decisiones de ruteo.
Ventajas:
- Adaptación dinámica
- Mejora continua del rendimiento
Desventajas:
- Requiere datos de entrenamiento
- Mayor consumo computacional
Laboratorio Espacial!
La NASA da recursos a desarrolladores para probar este tipo de comunicaciones con software diseñado por ellos. Podes revisarlos acá: https://www.nasa.gov/technology/space-comms/delay-disruption-tolerant-networking-mission-resources/
De ahí podemos sacar algunas herramientas para hacer pruebas locales de como funcionan estos sistemas.
Traté de probar como funciona DTN con una de las herramientas disponibles de la NASA: https://github.com/dtn7/dtn7-go
Para instalarla:
git clone https://github.com/dtn7/dtn7-go.git
cd dtn7-go
go build ./cmd/dtnd
go build ./cmd/dtnclient
#Necesitas tener instalado Go (golang)La idea del laboratorio es la siguiente:
Vamos a crear 3 nodos, ter_a, ter_b y ter_c. El A será la tierra, el B será la «mula» que lleva el tráfico a los satelites más lejanos (Marte por ejemplo) y el C, que mantendremos apagado hasta el final, será el satelite que está pasando por detrás de Marte mientras A está enviando el mensaje.
Con el propósito de que todos tengamos el mismo escenario funcional cree un sh que hace el trabajo del test por nosotros.
Acá la configuración de los 3 «satélites».
node_id = "dtn://ter_a/"
log_level = "Info"
[Store]
path = "/tmp/dtn_store_a"
[Routing]
algorithm = "epidemic"
[Agents.REST]
address = "localhost:8081"
[Agents.UNIX]
socket = "/tmp/dtnd_a.socket"
[[Listener]]
type = "MTCP"
address = ":4001"
[[Discovery.Static]]
node = "dtn://ter_b/"
endpoint = "mtcp://localhost:4002"
[Cron]
dispatch = "2s"
gc = "1h"node_id = "dtn://ter_b/"
log_level = "Info"
[Store]
path = "/tmp/dtn_store_b"
[Routing]
algorithm = "epidemic"
[Agents.REST]
address = "localhost:8082"
[Agents.UNIX]
socket = "/tmp/dtnd_b.socket"
[[Listener]]
type = "MTCP"
address = ":4002"
[[Discovery.Static]]
node = "dtn://ter_a/"
endpoint = "mtcp://localhost:4001"
[Cron]
dispatch = "2s"
gc = "1h"
node_id = "dtn://ter_c/"
log_level = "Info"
[Store]
path = "/tmp/dtn_store_c"
[Routing]
algorithm = "epidemic"
[Agents.REST]
address = "localhost:8083"
[Agents.UNIX]
socket = "/tmp/dtnd_c.socket"
[[Listener]]
type = "MTCP"
address = ":4003"
[[Discovery.Static]]
node = "dtn://ter_b/"
endpoint = "mtcp://localhost:4002"
[[Discovery.Static]]
node = "dtn://ter_b/"
endpoint = "mtcp://localhost:4002"
[Cron]
dispatch = "2s"
gc = "1h"
El archivo lab.sh es el más complejo. Después de muchos intentos no podía obtener todos los datos como quería. Habría 4 ventanas, hacía tail en cada una de los logs de cada term y siempre algo me faltaba. Acá chatgpt me dió una mano con un sh que gestiona y da los reportes uno a uno.
Cada nodo se levanta como un servicio y se ejecuta en background manejando la comunicación con sus pares. Dtn7 genera un servicio para la consulta del estado que se chequea desde un navegador (o en el script con curl). Este servicio supongo que es muy util para consultar desde un sistema embebido corriendo la app remotamente. Les dejo el lab.sh:
#!/bin/bash
# ============================================================
# Laboratorio DTN - Tolerancia a desconexión
# Escenario: A envía a C (apagado). B guarda. C enciende y recibe.
#
# Topología: A ←→ B ←→ C
# C se apaga, A envía bundle a dtn://ter_c/inbox.
# B lo guarda (store). C vuelve a encender (forward).
# ============================================================
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
# Usar el dtnd parcheado incluido en este directorio (con entrega retroactiva)
export PATH="$SCRIPT_DIR:$PATH"
LOG_A="/tmp/dtn_log_a.txt"
LOG_B="/tmp/dtn_log_b.txt"
LOG_C="/tmp/dtn_log_c.txt"
SOCKET_A="/tmp/dtnd_a.socket"
SOCKET_B="/tmp/dtnd_b.socket"
SOCKET_C="/tmp/dtnd_c.socket"
REST_A="http://localhost:8081/rest"
REST_B="http://localhost:8082/rest"
REST_C="http://localhost:8083/rest"
RED='\033[0;31m'; GREEN='\033[0;32m'; YELLOW='\033[1;33m'
CYAN='\033[0;36m'; BOLD='\033[1m'; NC='\033[0m'
sep() { echo -e "${CYAN}──────────────────────────────────────────────────${NC}"; }
paso() { echo; sep; echo -e "${BOLD}${YELLOW} PASO $1: $2${NC}"; sep; }
ok() { echo -e "${GREEN} ✓ $1${NC}"; }
info() { echo -e " $1"; }
err() { echo -e "${RED} ✗ $1${NC}"; }
# Espera a que el REST server de un nodo esté disponible
esperar_rest() {
local url="$1/register"
local nombre="$2"
local intentos=0
while [ $intentos -lt 30 ]; do
if curl -s -o /dev/null -w "%{http_code}" -X POST "$url" -H "Content-Type: application/json" \
-d '{}' 2>/dev/null | grep -q "200"; then
ok "$nombre REST listo ($url)"
return 0
fi
sleep 0.3
intentos=$((intentos + 1))
done
err "$nombre REST no respondió en tiempo"
exit 1
}
# Espera a que el socket UNIX esté disponible
esperar_socket() {
local socket="$1"
local nombre="$2"
local intentos=0
while [ ! -S "$socket" ] && [ $intentos -lt 20 ]; do
sleep 0.2
intentos=$((intentos + 1))
done
if [ -S "$socket" ]; then
ok "$nombre UNIX socket listo"
else
err "$nombre UNIX socket no apareció"
exit 1
fi
}
# Registra endpoint vía REST y devuelve el UUID
rest_register() {
local rest_url="$1"
local eid="$2"
local resp
resp=$(curl -s -X POST "$rest_url/register" \
-H "Content-Type: application/json" \
-d "{\"endpoint_id\": \"$eid\"}")
local uuid
uuid=$(echo "$resp" | grep -o '"uuid":"[^"]*"' | cut -d'"' -f4)
if [ -z "$uuid" ]; then
err "Registro fallido en $rest_url para $eid: $resp"
return 1
fi
echo "$uuid"
}
# Envía bundle vía REST
rest_send() {
local rest_url="$1"
local uuid="$2"
local source="$3"
local destination="$4"
local payload="$5"
local resp
resp=$(curl -s -X POST "$rest_url/build" \
-H "Content-Type: application/json" \
-d "{
\"uuid\": \"$uuid\",
\"arguments\": {
\"destination\": \"$destination\",
\"source\": \"$source\",
\"creation_timestamp_now\": 1,
\"lifetime\": \"24h\",
\"payload_block\": \"$payload\"
}
}")
echo "$resp"
}
# Recibe bundles vía REST
rest_fetch() {
local rest_url="$1"
local uuid="$2"
local resp
resp=$(curl -s -X POST "$rest_url/fetch" \
-H "Content-Type: application/json" \
-d "{\"uuid\": \"$uuid\"}")
echo "$resp"
}
# ============================================================
paso 0 "LIMPIEZA"
# ============================================================
info "Matando dtnd previos..."
pkill -9 dtnd 2>/dev/null
sleep 1
info "Borrando stores y logs anteriores..."
rm -rf /tmp/dtn_store_a /tmp/dtn_store_b /tmp/dtn_store_c
rm -f "$SOCKET_A" "$SOCKET_B" "$SOCKET_C"
rm -f "$LOG_A" "$LOG_B" "$LOG_C"
ok "Limpieza completa"
# ============================================================
paso 1 "INICIAR TER_A y TER_B (TER_C permanece APAGADO)"
# ============================================================
info "Iniciando nodo A (dtn://ter_a/ → puerto 4001, REST 8081)..."
dtnd "$SCRIPT_DIR/ter_A.toml" > "$LOG_A" 2>&1 &
PID_A=$!
info " PID ter_A = $PID_A"
info "Iniciando nodo B (dtn://ter_b/ → puerto 4002, REST 8082)..."
dtnd "$SCRIPT_DIR/ter_B.toml" > "$LOG_B" 2>&1 &
PID_B=$!
info " PID ter_B = $PID_B"
info " ► TER_C está APAGADO"
echo
info "Esperando REST servers de A y B..."
esperar_rest "$REST_A" "ter_A"
esperar_rest "$REST_B" "ter_B"
info "Esperando 3s para que A y B se descubran entre sí..."
sleep 3
echo
info "=== LOG TER_A (últimas 5 líneas) ==="
tail -5 "$LOG_A"
echo
info "=== LOG TER_B (últimas 5 líneas) ==="
tail -5 "$LOG_B"
# ============================================================
paso 2 "ENVIAR MENSAJE desde TER_A → TER_C"
# ============================================================
PAYLOAD="Hola TER_C! Bundle DTN enviado mientras estabas apagado. [$(date)]"
info "Origen : dtn://ter_a/sender"
info "Destino : dtn://ter_c/inbox"
info "Payload : $PAYLOAD"
echo
info "Registrando endpoint sender en ter_A (vía REST)..."
UUID_A=$(rest_register "$REST_A" "dtn://ter_a/sender")
ok "UUID ter_A = $UUID_A"
echo
info "Enviando bundle (A → C, C está APAGADO)..."
SEND_RESP=$(rest_send "$REST_A" "$UUID_A" "dtn://ter_a/sender" "dtn://ter_c/inbox" "$PAYLOAD")
info "Respuesta: $SEND_RESP"
if echo "$SEND_RESP" | grep -q '"error":""'; then
ok "Bundle enviado correctamente"
else
err "Error al enviar: $SEND_RESP"
fi
# ============================================================
paso 3 "VER ESTADO: BUNDLE GUARDADO EN TER_B (TER_C sigue apagado)"
# ============================================================
info "Esperando 5s para que A propague el bundle a B..."
sleep 5
echo
info "=== LOG TER_A ==="
cat "$LOG_A"
echo
info "=== LOG TER_B ==="
cat "$LOG_B"
echo
info "► Verificar en LOG TER_B: debe aparecer que recibió el bundle"
info " (No lo puede entregar a C porque C está apagado)"
# ============================================================
paso 4 "ENCENDER TER_C"
# ============================================================
info "► Iniciando nodo C (dtn://ter_c/ → puerto 4003, REST 8083)..."
dtnd "$SCRIPT_DIR/ter_C.toml" > "$LOG_C" 2>&1 &
PID_C=$!
info " PID ter_C = $PID_C"
echo
info "Esperando REST server de C..."
esperar_rest "$REST_C" "ter_C"
# ============================================================
# CRÍTICO: Registrar el endpoint en C ANTES de que llegue el
# bundle. El REST server inicia ANTES que el TCP listener y el
# discovery manager, por eso podemos registrar primero.
# ============================================================
info "Registrando endpoint inbox en ter_C vía REST (ANTES del discovery)..."
UUID_C=$(rest_register "$REST_C" "dtn://ter_c/inbox")
ok "UUID ter_C = $UUID_C"
ok "Endpoint dtn://ter_c/inbox registrado en C"
# ============================================================
paso 5 "ESPERAR ENTREGA Y RECIBIR EN TER_C"
# ============================================================
info "Esperando 8s para que B detecte C y entregue el bundle guardado..."
sleep 8
echo
info "=== LOG TER_C ==="
cat "$LOG_C"
echo
info "=== LOG TER_B (completo) ==="
cat "$LOG_B"
echo
info "Recuperando bundles del mailbox de ter_C (vía REST)..."
FETCH_RESP=$(rest_fetch "$REST_C" "$UUID_C")
echo
# El payload viene en base64 en el campo "data" del payloadBlock
PAYLOAD_B64=$(echo "$FETCH_RESP" | python3 -c "
import sys, json, base64
try:
d = json.load(sys.stdin)
for b in d.get('bundles', []):
pb = b.get('payloadBlock', {})
data = pb.get('data', '')
if data:
print(base64.b64decode(data).decode('utf-8', errors='replace'))
except: pass
" 2>/dev/null)
if echo "$PAYLOAD_B64" | grep -q "Hola TER_C"; then
echo
echo -e "${GREEN}${BOLD} ╔══════════════════════════════════════════════╗${NC}"
echo -e "${GREEN}${BOLD} ║ BUNDLE RECIBIDO EXITOSAMENTE EN TER_C ║${NC}"
echo -e "${GREEN}${BOLD} ╚══════════════════════════════════════════════╝${NC}"
echo -e "${GREEN} Mensaje: $PAYLOAD_B64${NC}"
echo
echo -e "${GREEN} JSON completo:${NC}"
echo "$FETCH_RESP" | python3 -m json.tool 2>/dev/null || echo "$FETCH_RESP"
else
echo -e "${YELLOW} Respuesta fetch:${NC}"
echo "$FETCH_RESP" | python3 -m json.tool 2>/dev/null || echo "$FETCH_RESP"
echo
echo -e "${YELLOW} Si bundles=[] intentar de nuevo en unos segundos:${NC}"
info " curl -s -X POST http://localhost:8083/rest/fetch -H 'Content-Type: application/json' \\"
info " -d '{\"uuid\": \"$UUID_C\"}'"
fi
# ============================================================
paso 6 "LOGS COMPLETOS Y RESUMEN"
# ============================================================
echo
echo -e "${BOLD}=== LOG TER_A ===${NC}"
cat "$LOG_A"
echo
echo -e "${BOLD}=== LOG TER_B ===${NC}"
cat "$LOG_B"
echo
echo -e "${BOLD}=== LOG TER_C ===${NC}"
cat "$LOG_C"
sep
echo -e "${BOLD}Resumen del laboratorio:${NC}"
echo " 1. A envió bundle → B lo almacenó (C estaba APAGADO)"
echo " 2. C encendió → se registró el endpoint → B envió el bundle"
echo " 3. C recibió el bundle guardado (store-and-forward DTN)"
echo
echo -e "${BOLD}PIDs activos:${NC}"
echo " ter_A: $PID_A ter_B: $PID_B ter_C: $PID_C"
echo
echo -e " Comandos útiles:"
echo -e " Volver a buscar en C: ${YELLOW}curl -s -X POST $REST_C/fetch -H 'Content-Type: application/json' -d '{\"uuid\": \"$UUID_C\"}'${NC}"
echo -e " Detener todo: ${YELLOW}pkill dtnd${NC}"
sep
Tuve problemas cada vez que reiniciaba cada nodo y aprendí a los golpes que hay que frenar cada hilo y limpiar logs y temporales.
Al terminar el lab, para poder seguir practicando no olvidar correr:
#Matar los nodos
pkill -9 dtnd 2>/dev/null
#Limpiar logs creados en el lab
rm -rf /tmp/dtn_store_a /tmp/dtn_store_b /tmp/dtn_store_cUstedes podran obtener los resultados, les dejo los mios.
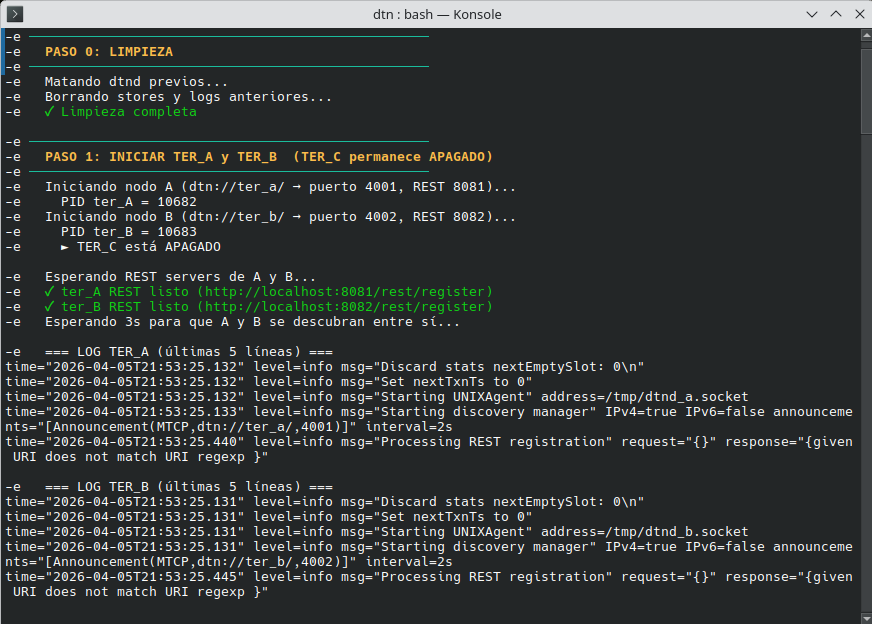
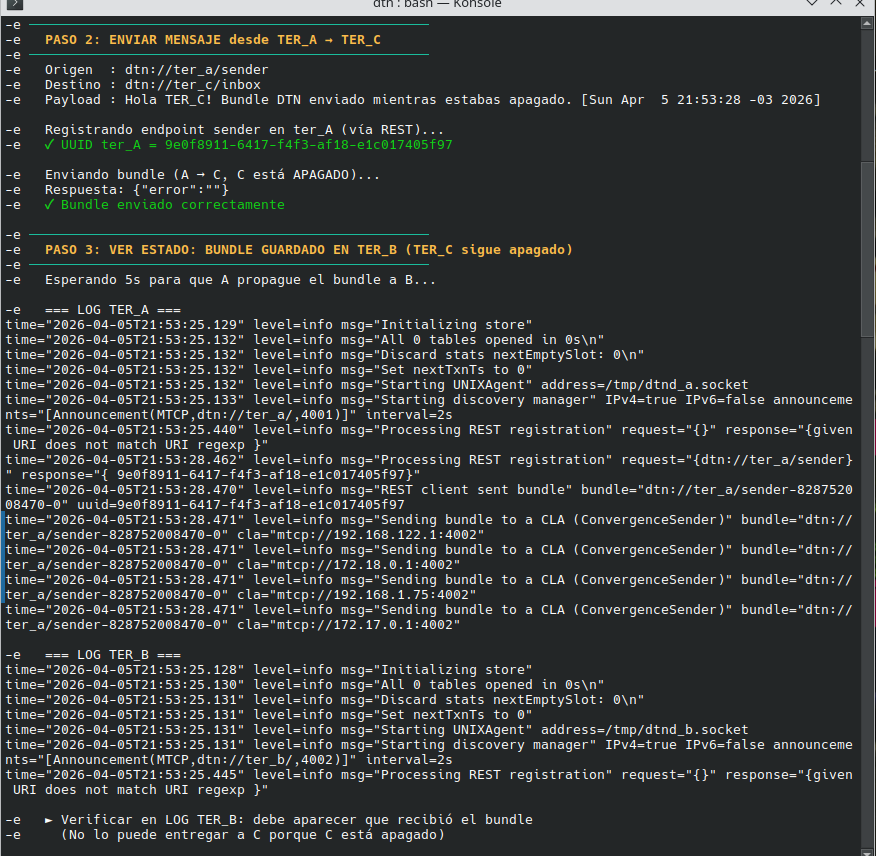
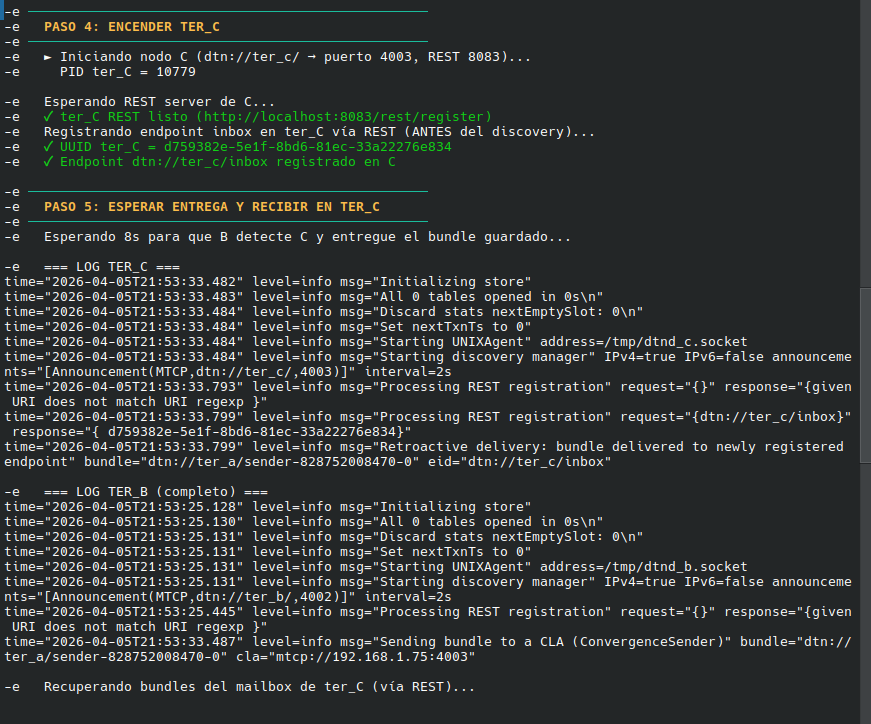
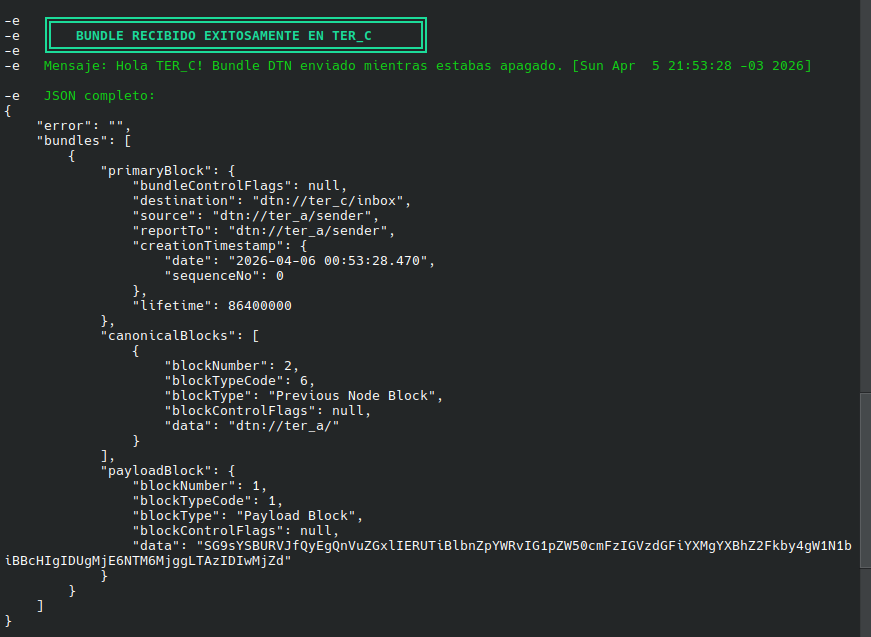
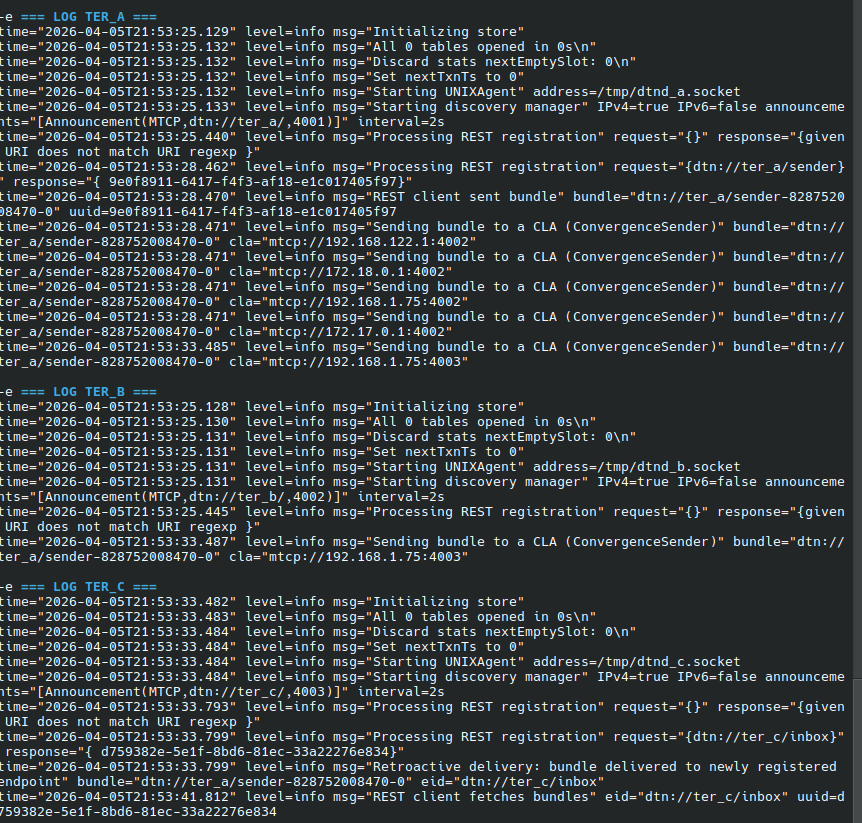
Noten la marca horaria en el mensaje enviado y los detalles del payload, la información hasheada y el log detallado que da dtn7-go. Creo que voy a tener que seguir practicando hasta verlo en un sistema embebido real.
Escenarios de Catástrofe
Quizás me fui por lo espacial todo el artículo por gusto, obviamente, pero estos algoritmos se usan muchísimo para comunicaciones en escenarios de catástrofes o entornos aislados. (Ya casi inexistentes desde Starlink)
Hay un proyecto que encontré un tanto desactualizado, Serval Project https://github.com/servalproject que tenía como objeto despliegues rápidos de infraestructura en catástrofes naturales que me llamó mucho la atención. Traté de usar la apk pero está muy desactualizada así que, en companía de Claude, desarrollé una app similar para Android y la publiqué en Github.
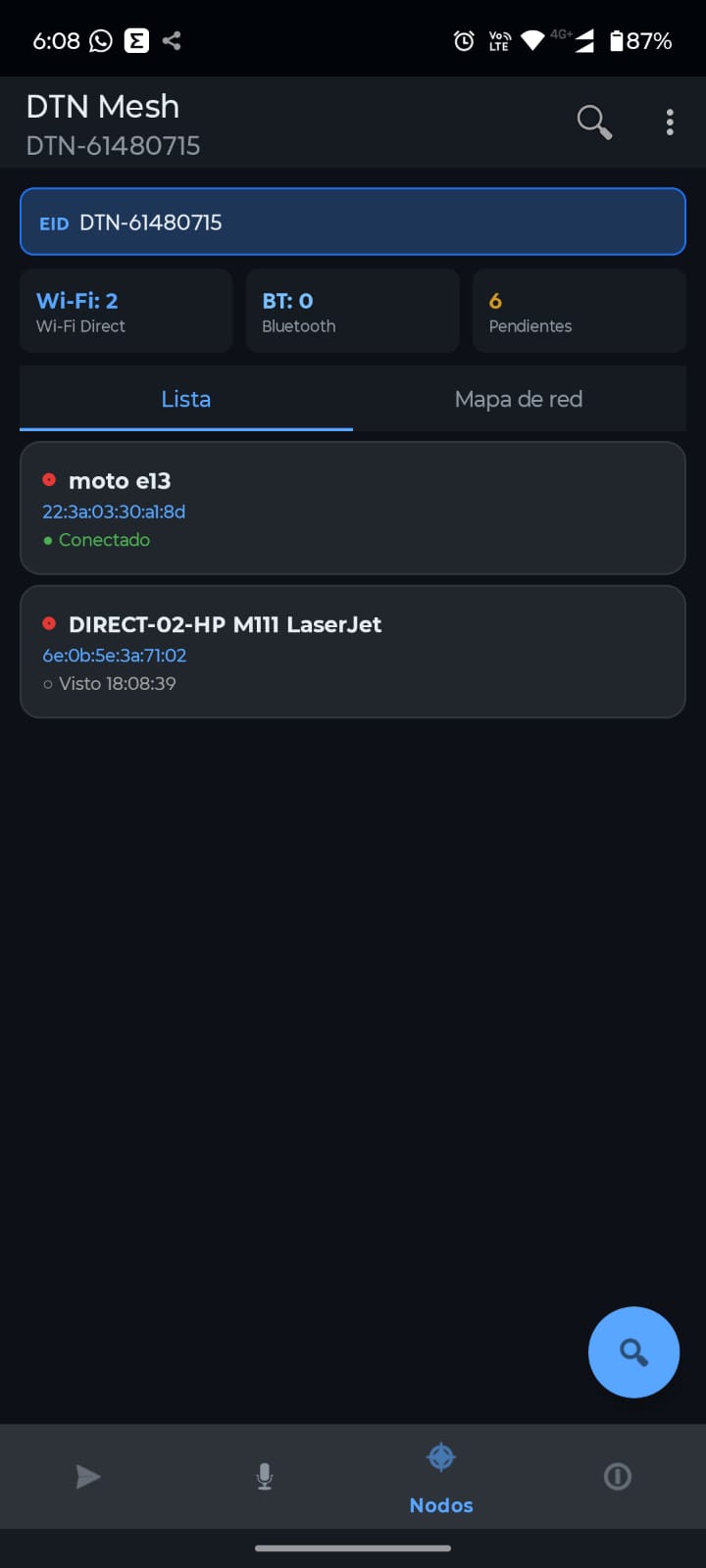
DTN Mesh
DTN Mesh funciona en Android, el proyecto está disponible para el que lo quiera usar. Espero poder hacerle mejoras con el tiempo.
La idea es usar Prophet para conectar nodos android sin infraestructura adyante. Seguramente lo usaré en la montaña cuando toque escalar y espero no en una catastrofe real pero está a disposición del que lo quiera usar y darme su feedback. Colgué el último build en releases para que puedas probarlo.
Tiene fallas, en un fin de semana no podía salir algo funcional y copado al mismo tiempo, pero cumple como PoC (prueba de concepto) de un sistema con estas características.
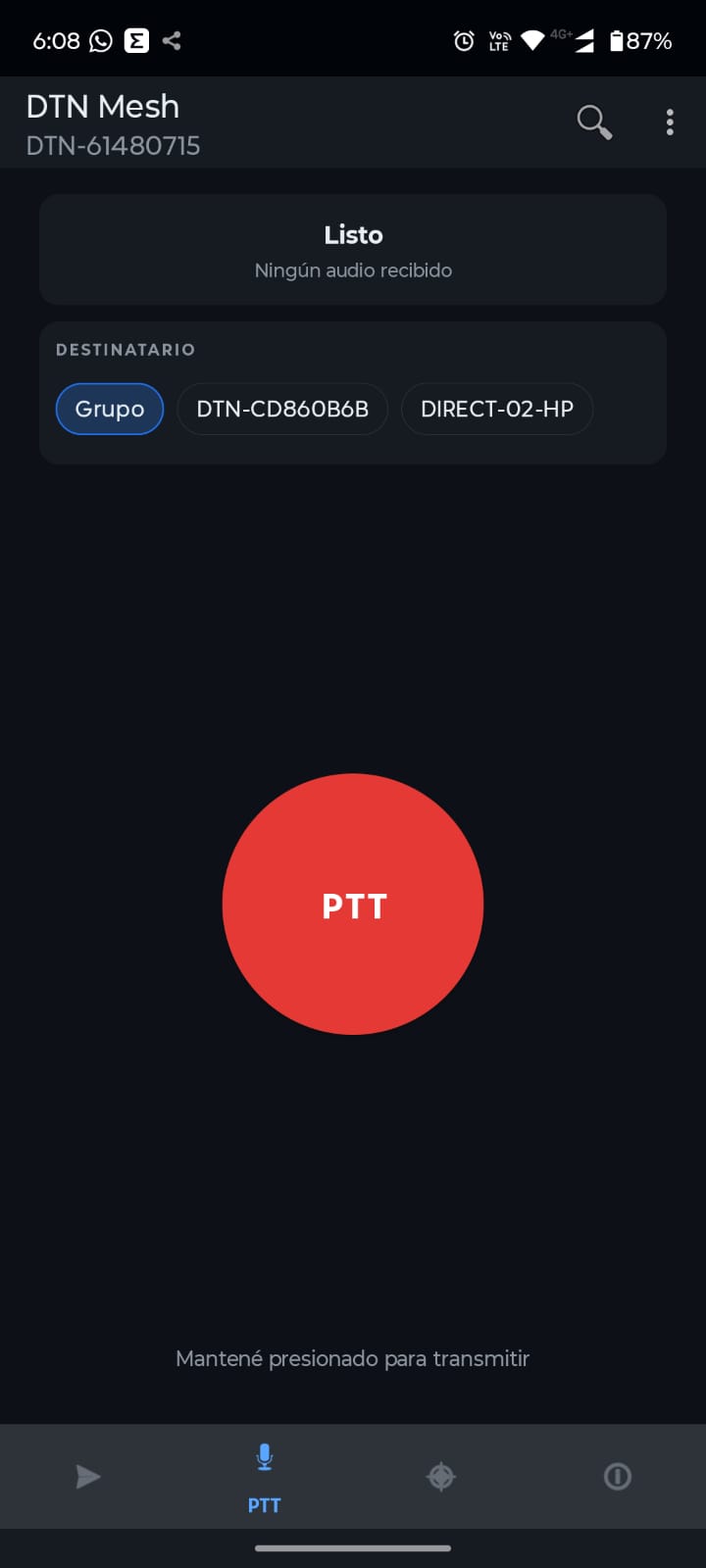
Los nodos están todo el tiempo buscándose usando WiFi Direct y Bluetooth, eso hace que a veces los mensajes queden en cola mucho tiempo antes de enviarse. No alcancé a probar el módulo LoRa pero Claudo quiso que lo incluyamos y el software no es muy bueno detectando cuál equipo encontrado corre un server y cuál no. Aún así funciona y al cabo de unos 30/120 segundos envía un mensaje o un audio.
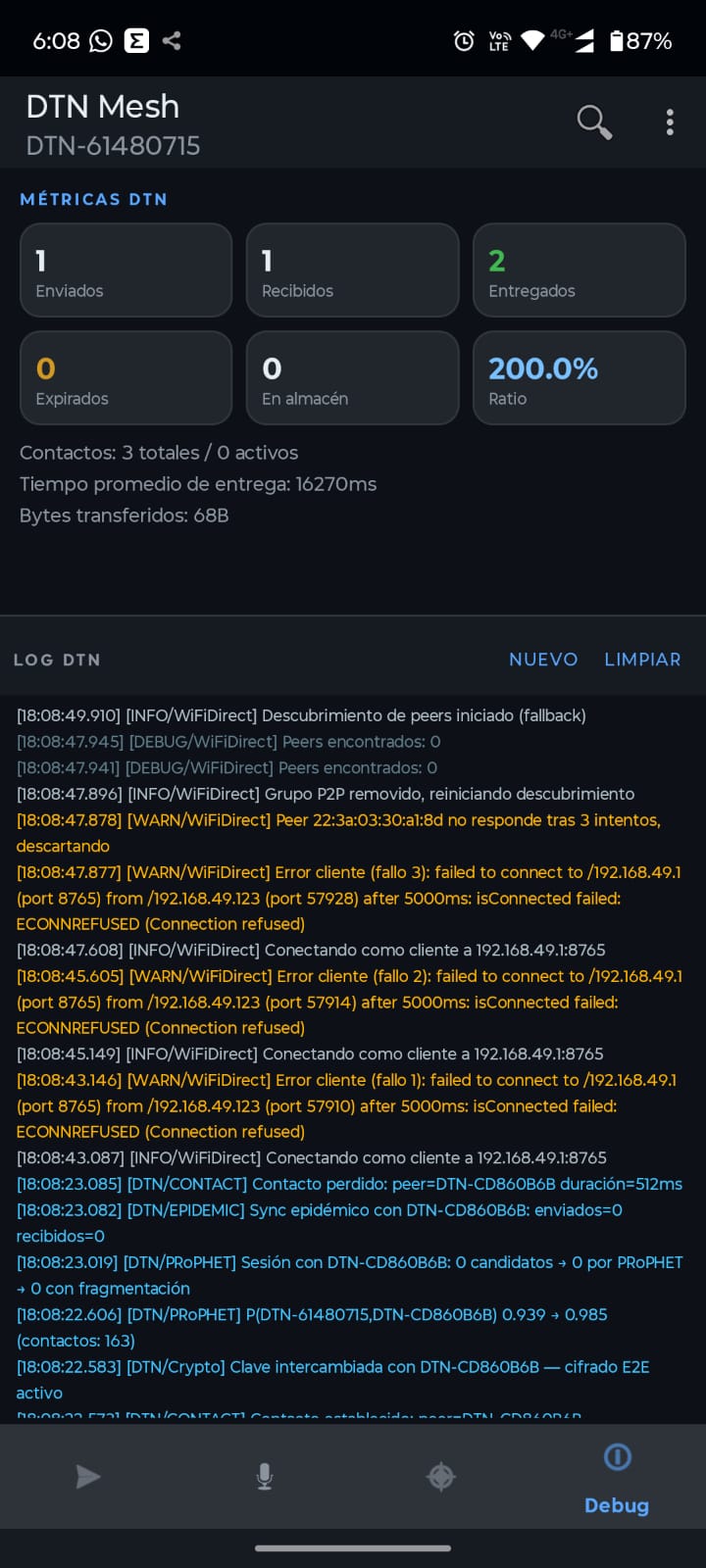
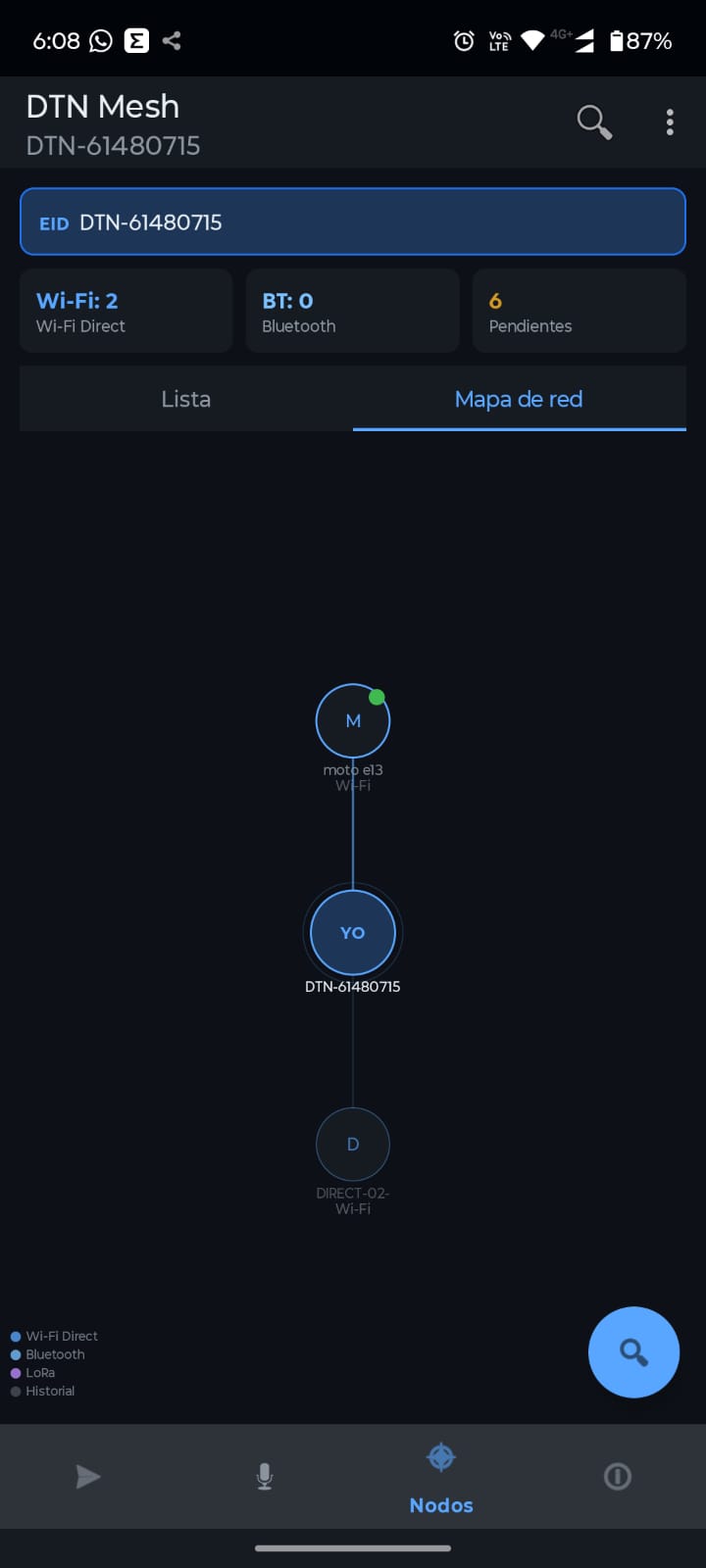
Les dejo el link del repo: https://github.com/jeremiaspala/dtn-mesh y acepto cualquier opción de mejora ya que… bueno, es un test… complejo, pero test al fin.
Conclusiones
Los algoritmos de ruteo en DTN representan distintas estrategias para resolver el problema fundamental de la entrega de mensajes en redes con conectividad intermitente. Todos los enfoques, desde los más simples basados en inundación hasta modelos avanzados basados en contexto y aprendizaje, la elección del algoritmo depende del entorno, los recursos disponibles y los objetivos del sistema apuntan a la comunicación eficáz en lugares o momentos donde es muy dificil lograrla.
En aplicaciones reales, especialmente en escenarios de catástrofe, los enfoques híbridos que combinan replicación controlada de los bundles con decisiones probabilísticas ofrecen el mejor equilibrio entre eficiencia y confiabilidad; y así también son los más dificiles de implementar.
En el espacio, DTN, es esencial pero aquí?. Hoy en día las soluciones satelitales dan soluciones modernas a problemas de esta índole. Starlink cambió el mapa global y brindó accesos a lugares donde antes era imposible tener algún tipo de conectividad. La pregunta es: Y si falla?. DTN en tierra es una solución valedera a un problema profundo y quizás bastante más actual de lo que creemos.